Materialized View Checkpoint
Timeplus Materialized Views support multiple checkpointing strategies to address different deployment scenarios. Conceptually, it is similar to Apache Flink’s checkpointing, but with significant implementation differences.
In general, the checkpoint coordinator periodically sends checkpoint markers to the source nodes of the query DAG. These markers flow through the DAG, and when stateful nodes detect them, they serialize their in-memory state to the local file system. The checkpoint files are then copied/replicated to the target storage.
The following diagram illustrates this process:
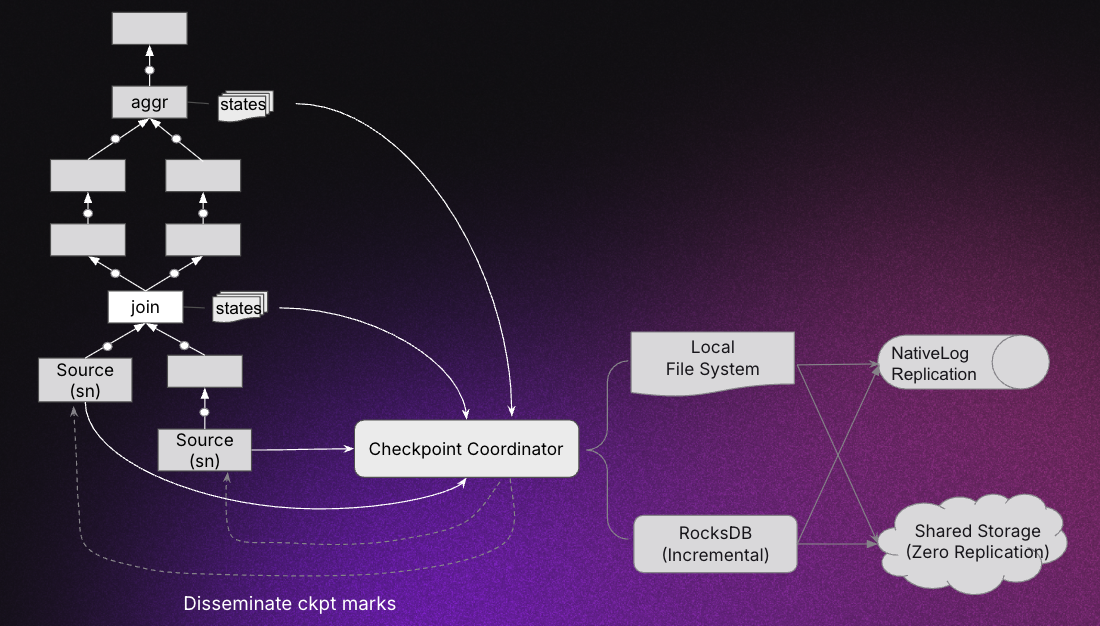
Each checkpoint round is assigned a new checkpoint epoch. Once a new checkpoint epoch is committed, older epochs can be garbage collected automatically.
Local File System Checkpoint
This is the default checkpointing mechanism in single-instance Timeplus deployments and is reused in replicated checkpoint.
How it works:
- The checkpoint coordinator periodically triggers full checkpoints on the Materialized View query DAG.
- Stateful nodes in the DAG serialize their in-memory state to the local file system in their native data format.
This approach is simple and effective for standalone or development setups.
Local RocksDB Checkpoint
When hybrid hash tables are enabled for streaming joins and/or aggregations, Timeplus automatically switches to RocksDB-based incremental checkpointing.
Key differences from local file system checkpointing:
- Only changed keys are written in each checkpoint, instead of the full state.
- Each checkpoint epoch builds on the previous ones, forming a dependency chain. The first epoch acts as the base checkpoint.
- Periodic compaction merges incremental checkpoints into a consolidated snapshot to prevent fragmentation.
- To restore a complete state, multiple epochs may be merged together.
This strategy greatly reduces checkpointing overhead for large, stateful streaming workloads, particularly when updates are limited to a small set of hot keys.
Replicated Checkpoint
In a cluster environment, checkpoints must be replicated to peer Materialized View replicas to ensure fault tolerance and high availability.
In this mode (applies to both local file system checkpoints and RocksDB-based incremental checkpoints), after the checkpoint coordinator creates a new checkpoint epoch locally, it replicates the state data of that epoch through the Materialized View’s internal NativeLog, which leverages Raft consensus for replication.
Checkpoint process:
- The checkpoint coordinator serializes query states to the local file system in a new epoch.
- It then asynchronously packages the state files into NativeLog records (splitting large files if necessary), appends them to the log, and replicates them to peer replicas via Raft.
- Peer replicas consume these checkpoint records from the log and reconstruct them into checkpoint files for the current epoch.
- After replication completes, all Materialized View replicas hold identical checkpoint states.
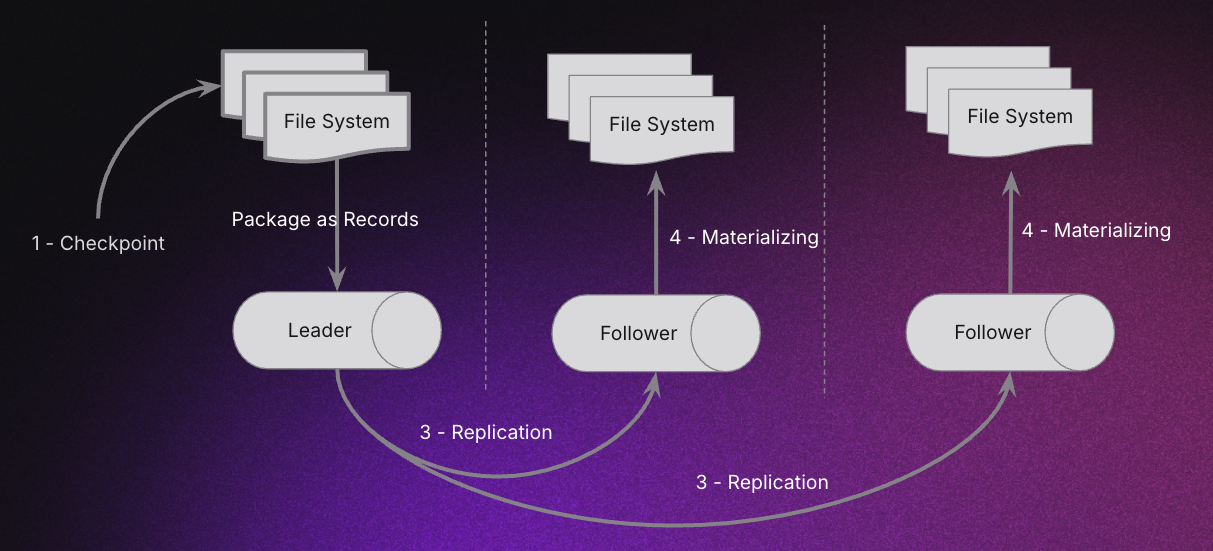
By default, NativeLog-based checkpoint replication is used in cluster environments.
Example:
-- Create the source stream
CREATE STREAM source(i int, s string);
-- Create the sink stream
CREATE STREAM sink(win_start datetime64(3), total int, s string);
-- Use NativeLog for checkpoint replication
CREATE MATERIALIZED VIEW nlog_ckpt_rep INTO sink
AS
SELECT
window_start AS win_start,
s,
sum(i)
FROM tumble(source, 5s)
GROUP BY window_start, s;
Zero Replication Checkpoint
Like Replicated Checkpoint, Zero Replication Checkpoint provides high availability and fault tolerance in a cluster as well. However, instead of replicating checkpoints via NativeLog, it leverages shared storage (e.g., S3) to persist checkpoints. Since shared storage already ensures durability and replication, additional replication is unnecessary.
There are two variants:
Shared Storage
Checkpoint process:
- The checkpoint coordinator serializes query states to the local file system in a new epoch.
- It asynchronously uploads the state files for that epoch to shared storage.

When using shared storage exclusively, Timeplus adopts a different high availability model for Materialized Views, governed by a centralized scheduler.
Example:
-- Create the source stream
CREATE STREAM source(i int, s string);
-- Create the sink stream
CREATE STREAM sink(win_start datetime64(3), total int, s string);
-- Create s3 shared disk
CREATE DISK s3_plain_disk disk(
type = 's3_plain',
-- metadata_type='plain',
endpoint = 'http://localhost:9000/disk/checkpoint/',
access_key_id = 'minioadmin',
secret_access_key = 'minioadmin',
skip_access_check=0
);
-- Use shared storage for checkpoint replication
CREATE [SCHEDULED] MATERIALIZED VIEW shared_ckpt_rep INTO sink
AS
SELECT
window_start as win_start,
s,
sum(i)
FROM tumble(source, 5s)
GROUP BY window_start, s
SETTINGS
checkpoint_settings='replication_type=shared;shared_disk=s3_plain_disk';
NativeLog + Shared Storage
This hybrid approach combines NativeLog with shared storage.
Checkpoint process:
- The checkpoint coordinator serializes query states to the local file system in a new epoch.
- It asynchronously uploads the state files to shared storage.
- It commits the object URIs / paths metadata records to NativeLog.
- Peer replicas consume these path metadata records, fetch the checkpoint files from shared storage, and reconstruct the checkpoint locally.

Example:
-- Create the source stream
CREATE STREAM source(i int, s string);
-- Create the sink stream
CREATE STREAM sink(win_start datetime64(3), total int, s string);
-- Create S3-backed shared disk
CREATE DISK s3_plain_disk DISK(
type = 's3_plain',
endpoint = 'http://localhost:9000/disk/checkpoint/',
access_key_id = 'minioadmin',
secret_access_key = 'minioadmin',
skip_access_check = 0
);
-- Use shared storage + NativeLog for checkpoint replication
CREATE MATERIALIZED VIEW shared_nlog_ckpt_rep INTO sink
AS
SELECT
window_start AS win_start,
s,
SUM(i)
FROM tumble(source, 5s)
GROUP BY window_start, s
SETTINGS
checkpoint_settings = 'replication_type=nativelog;shared_disk=s3_plain_disk';
-- RocksDB-based incremental checkpoint with shared storage + NativeLog
CREATE MATERIALIZED VIEW rocks_shared_nlog_ckpt_rep INTO sink
AS
SELECT
window_start AS win_start,
s,
SUM(i)
FROM tumble(source, 5s)
GROUP BY window_start, s
SETTINGS
default_hash_table = 'hybrid', -- Uses RocksDB for incremental checkpoints
checkpoint_settings = 'replication_type=nativelog;shared_disk=s3_plain_disk';
Choosing the Right Replication Strategy
In cluster deployments, there are three options for checkpoint replication:
- NativeLog-based replication (pure Raft-based).
- Shared Storage replication (zero replication).
- Hybrid replication (NativeLog + Shared Storage).
When to Use Each ?
-
On-prem deployments without shared storage: Use NativeLog-based replication, as it is the only option.
-
Deployments with shared (cloud) storage: You can choose between Shared Storage or Hybrid replication. The decision depends on workload characteristics, Materialized View elasticity requirements, and operational trade-offs because these two replications strategies have different high availability models. For more details, see the Materialized View High Availability documentation.